 I recently helped Dave Winer debug his OAuth Consumer code, and the process was more painful than it should have been. (He was trying to write a Twitter app using their beta OAuth support, and since he has his own scripting environment for his OPML editor, there wasn’t an existing library he could just drop in.) Now I’m a big fan of OAuth–it’s a key piece of the Open Stack, and it really does work well once you get it working. I’ve written both OAuth Provider and Consumer code in multiple languages and integrated with OAuth-protected APIs on over half a dozen sites. I’ve also helped a lot of developers and companies debug their OAuth implementations and libraries. And the plain truth is this: it’s empirically way too painful still for first-time OAuth developers to get their code working, and despite the fact that OAuth is a standard, the empirical “it-just-works-rate” is way too low.
I recently helped Dave Winer debug his OAuth Consumer code, and the process was more painful than it should have been. (He was trying to write a Twitter app using their beta OAuth support, and since he has his own scripting environment for his OPML editor, there wasn’t an existing library he could just drop in.) Now I’m a big fan of OAuth–it’s a key piece of the Open Stack, and it really does work well once you get it working. I’ve written both OAuth Provider and Consumer code in multiple languages and integrated with OAuth-protected APIs on over half a dozen sites. I’ve also helped a lot of developers and companies debug their OAuth implementations and libraries. And the plain truth is this: it’s empirically way too painful still for first-time OAuth developers to get their code working, and despite the fact that OAuth is a standard, the empirical “it-just-works-rate” is way too low.
We in the Open Web community should all be concerned about this, since OAuth is the “gateway” to most of the open APIs we’re building, and quite often this first hurdle is the hardest one in the entire process. That’s not the “smooth on-ramp” we should be striving for here. We can and should do better, and I have a number of suggestions for how to do just that.
To some extent, OAuth will always be “hard” in the sense that it’s crypto–if you get one little bit wrong, the whole thing doesn’t work. The theory is, “yeah it might be hard the first time, but at least you only have to suffer that pain once, and then you can use it everywhere”. But even that promise falls short because most OAuth libraries and most OAuth providers have (or have had) bugs in them, and there aren’t good enough debugging, validating, and interop tools available to raise the quality bar without a lot of trial-and-error testing and back-and-forth debugging. I’m fortunate in that a) I’ve written and debugged OAuth code so many times that I”m really good at it now, and b) I personally know developers at most of the companies shipping OAuth APIs, but clearly most developers don’t have those luxuries, nor should they have to.
After I helped Dave get his code working, he said “you know, what you manually did for me was perfect. But there should have been a software tool to do that for me automatically”. He’s totally right, and I think with a little focused effort, the experience of implementing and debugging OAuth could be a ton better. So here are my suggestions for how to help make implementing OAuth easier. I hope to work on some or all of these in my copious spare time, and I encourage everyone that cares about OAuth and the Open Stack to pitch in if you can!
- Write more recipe-style tutorials that take developers step-by-step through the process of building a simple OAuth Consumer that works with a known API in a bare-bones, no-fluff fashion. There are some good tutorials out there, but they tend to be longer on theory and shorter on “do this, now do this, now you should see that, …”, which is what developers need most to get up and running fast. I’ve written a couple such recipes so far–one for becoming an OpenID relying party, and one for using Netflix’s API–and I’ve gotten tremendous positive feedback on both, so I think we just need more like that.
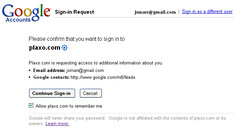
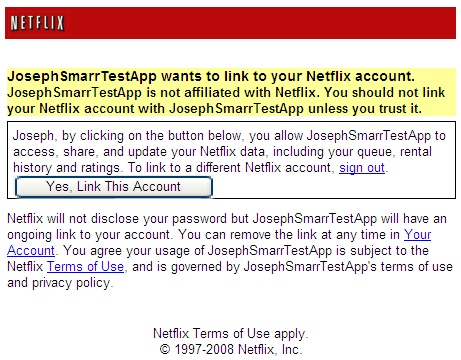
- Build a “transparent OAuth Provider” that shows the consumer exactly what signature base string, signature key, and signature it was expecting for each request. One of the most vexing aspects of OAuth is that if you make a mistake, you just get a 401 Unauthorized response with little or no debugging help. Clearly in a production system, you can’t expect the provider to dump out all the secrets they were expecting, but there should be a neutral dummy-API/server where you can test and debug your basic OAuth library or code with full transparency on both sides. In addition, if you’re accessing your own user-data on a provider’s site via OAuth, and you’ve logged in via username and password, there should be a special mode where you can see all the secrets, base strings, etc. that they’re expecting when you make an OAuth-signed request. (I plan to add this to Plaxo, since right now I achieve it by grepping through our logs and them IMing with the developers who are having problems, and this is, uhh, not scalable.)
- Build an OAuth validator for providers and consumers that simulates the “other half” of the library (i.e. a provider to test consumer-code and a consumer to test provider-code) and that takes the code through a bunch of different scenarios, with detailed feedback at each step. For instance, does the API support GET? POST? Authorization headers? Does it handle empty secrets properly? Does it properly encode special characters? Does it compute the signature properly for known values? Does it properly append parameters to the oauth_callback URL when redirecting? And so on. I think the main reason that libraries and providers so far have all had bugs is that they really didn’t have a good way to thoroughly test their code. As a rule, if you can’t test your code, it will have bugs. So if we just encoded the common mistakes we’ve all seen in the field so far and put those in a validator, future implementations could be confident that they’ve nailed all the basics before being released in the wild. (And I’m sure we’d uncover more bugs in our existing libraries and providers in the process!)
- Standardize the terms we use both in our tutorials and libraries. The spec itself is pretty consistent, but it’s already confusing enough to have a “Consumer Token”, “Request Token”, and “Access Token”, each of which consist of a “Token Key” and “Token Secret”, and it’s even more confusing when these terms aren’t used with exact specificity. It’s too easy to just say “token” to mean “request token” or “token” to mean “token key”–I do it all the time myself, but we really need to keep ourselves sharp when trying to get developers to do the right thing. Worse still, all the existing libraries use different naming conventions for the functions and steps involved, so it’s hard to write tutorials that work with multiple libraries. We should do a better job of using specific and standard terms in our tutorials and code, and clean up the stuff that’s already out there.
- Consolidate the best libraries and other resources so developers have an easier time finding out what the current state-of-the-art is. Questions that should have obvious and easily findable answers include: is there an OAuth library in my language? If so, what’s the best one to use? How much has it been tested? Are their known bugs? Who should I contact if I run into problems using it? What are the current best tutorials, validators, etc. for me to use? Which companies have OAuth APIs currently? What known issues exist for each of those providers? Where is the forum/mailing-list/etc for each of those APIs? Which e-mail list(s) should I send general OAuth questions to? Should I feel confident that emails sent to those lists will receive prompt replies? Should I expect that bug reports or patches I submit there will quickly find their way to the right place? And so on.
- Share more war stories of what we’ve tried, what hasn’t worked, and what we had to do to make it work. I applauded Dave for suffering his developer pain in public via his blog, and I did the same when working with Netflix’s API, but if we all did more of that, our collective knowledge of bugs, patterns, tricks, and solutions would be out there for others to find and benefit form. I should do more of that myself, and if you’ve ever tried to use OAuth, write an OAuth library, or build your own provider, you should too! So to get things started: In Dave’s case, the ultimate problem turned out to be that he was using his Request Secret instead of his Access Secret when signing API requests. Of course this worked when hitting the OAuth endpoint to get his Access token in the first place, and it’s a subtle difference (esp. if you don’t fully grok what all these different tokens are for, which most people don’t), but it didn’t work when hitting a protected API, and there’s no error message on any provider that says “you used the wrong secret when signing your request” since the secrets are never transmitted directly. The way I helped him debug it was to literally watch our debugging logs (which spit out all the guts of the OAuth signing process, including Base String, Signature Key, and final Signature), and then I sent him all that info and asked him to print out the same info on his end and compare the two. Once he did that, it was easy to spot and fix the mistake. But I hope you can see how all of the suggestions above would have helped make this process a lot quicker and less painful.
What else can we as a community do to make OAuth easier for developers? Add your thoughts here or in your own blog post. As Dave remarked to me, “the number of OAuth developers out there is about to skyrocket” now that Google, Yahoo, MySpace, Twitter, Netflix, TripIt, and more are providing OAuth-protected APIs. So this is definitely the time to put in some extra effort to make sure OAuth can really achieve its full potential!

 I’m excited and humbled by the amazing progress we’ve made this year on
I’m excited and humbled by the amazing progress we’ve made this year on 












{kind=link}