Tying it All Together: Implementing the Open Web
Web 2.0 Expo New York
New York, NY
September 19, 2008
Download PPT (7.2 MB)
 I gave the latest rev of my talk on how the social web is opening up and how the various building blocks (OpenID, OAuth, OpenSocial, PortableContacts, XRDS-Simple, Microformats, etc.) fit together to create a new social web ecosystem. Thanks to Kris Jordan, Mark Scrimshire, and Steve Kuhn for writing up detailed notes of what I said. Given that my talk was scheduled for the last time slot on the last day of the conference, it was well attended and the audience was enthusiastic and engaged, which I always take as a good sign.
I gave the latest rev of my talk on how the social web is opening up and how the various building blocks (OpenID, OAuth, OpenSocial, PortableContacts, XRDS-Simple, Microformats, etc.) fit together to create a new social web ecosystem. Thanks to Kris Jordan, Mark Scrimshire, and Steve Kuhn for writing up detailed notes of what I said. Given that my talk was scheduled for the last time slot on the last day of the conference, it was well attended and the audience was enthusiastic and engaged, which I always take as a good sign.
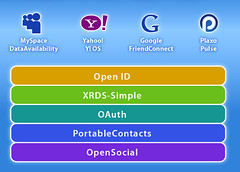 I think the reason that people are reacting so positively to this message (besides the fact that I’m getting better with practice at explaining these often complex technologies in a coherent way!) is that it’s becoming more real and more important every day. It’s amazing to me how much has happened in this space even since my last talk on this subject at Google I/O in May (I know because I had to update my slides considerably since then!). Yahoo has staked its future on going radically open with Y!OS, and it’s using the “open stack” to do it. MySpace hosted our Portable Contacts Summit (an important new building block), and is using OpenID, OAuth, and OpenSocial for it’s “data availability” platform. Google now uses OAuth for all of its GData APIs. These are three of the biggest, most mainstream consumer web businesses around, and they’re all going social and open in a big way.
I think the reason that people are reacting so positively to this message (besides the fact that I’m getting better with practice at explaining these often complex technologies in a coherent way!) is that it’s becoming more real and more important every day. It’s amazing to me how much has happened in this space even since my last talk on this subject at Google I/O in May (I know because I had to update my slides considerably since then!). Yahoo has staked its future on going radically open with Y!OS, and it’s using the “open stack” to do it. MySpace hosted our Portable Contacts Summit (an important new building block), and is using OpenID, OAuth, and OpenSocial for it’s “data availability” platform. Google now uses OAuth for all of its GData APIs. These are three of the biggest, most mainstream consumer web businesses around, and they’re all going social and open in a big way.
At the same time, the proliferation of new socially-enabled services continues unabated. This is why users and developers are increasingly receptive to an Open Web in which the need to constantly re-create and maintain accounts, profiles, friends-lists, and activity streams is reduced. And even though some large sites like Facebook continue to push a proprietary stack, they too see the value of letting their users take their data with them across the social web (which is precisely what Facebook Connect does). Thus all the major players are aligned in their view of the emerging “social web ecosystem” in which Identity Providers, Social Graph Providers, and Content Aggregators will help users interact with the myriad social tools we all want to use.
So basically: everyone agrees on the architecture, most also agree on the open building blocks, and nothing prevents the holdouts from going open if/when they decide it’s beneficial or inevitable. This is why I’m so optimistic and excited to be a part of this movement, and it’s why audiences are so glad to hear the good news.
PS: Another positive development since my last talk is that we’re making great progress on actually implementing the “open stack” end-to-end. One of the most compelling demos I’ve seen is by Brian Ellin of JanRain, which shows how a user can sign up for a new site and provide access to their private address book, all in a seamless and vendor-neutral way!
Liked this post? Follow this blog to get more.