I was invited to give a talk at the OpenID Summit as a follow-up to my talk “What an RP Wants“, which I gave in February at the OpenID Design Summit. In both cases, I shared my experiences from Plaxo’s perspective as a web site that is trying to succeed at letting users sign up using accounts they already have on Google, Yahoo, and other OpenID Provider sites. This talk reviewed the progress we’ve made as a community since February, and laid out the major remaining challenges to making it a truly-successful end-to-end experience to be an OpenID Relying Party (RP).
My basic message was this: we’ve made a lot of progress, but we’ve still got a lot left to do. So let’s re-double our efforts and commit ourselves once again to working together and solving these remaining problems. As much success as OpenID has had to date, its continued relevance is by no means guaranteed. But I remain optimistic because the same group of people that have brought us this far are still engaged, and none of the remaining challenges are beyond our collective ability to solve.
See more coverage of the OpenID Summit, including my talk, at The Real McCrea.
And here are a couple of video excerpts from my talk:
The kind Google I/O folks have now posted a full video of my recent talk, “The Social Web: An Implementer’s Guide“. They did a great job editing back and forth between me and my slides. If you weren’t able to make it to Google I/O (or you thought the talk was so good you want to see it again), then please check it out! 🙂
Google invited me back for a second year in a row to speak at their developer conference about the state-of-the-art of opening up the social web. While my talk last year laid out the promise and vision of an interoperable social web ecosystem, this year I wanted to show all the concrete progress we’ve made as an industry in achieving that goal. So my talk was full of demos–signing up for Plaxo with an existing Gmail account in just two clicks, using MySpaceID to jump into a niche music site without a separate sign-up step, ending “re-friend madness” by honoring Facebook friend connections on Plaxo (via Facebook Connect), killing the “password anti-pattern” with user-friendly contact importers from a variety of large sites (demonstrated with FriendFeed), and sharing activity across sites using Google FriendConnect and Plaxo. Doing live demos is always a risky proposition, especially when they involve cross-site interop, but happily all the demos worked fine and the talk was a big success!
I began my talk by observing that the events of the last year has made it clear: The web is going social, and the social web is going open. By the end of my talk, having showed so many mainstream sites with deep user-friendly and user-friendly interoperability, I decided to go a step further and declare: The web is now social, and the social web is now open. You don’t have to wait any longer to start reaping the benefits. It’s time to dive in.
You may remember the venerable IETF standards-body from such foundational internet RFCs as HTTP (aka the web), SMTP (aka e-mail), and vCard (aka contact info). So I’ll be honest that I was a bit intimidated when they invited me to their IETF-wide conference to speak about my work on Portable Contacts.
In addition to being chartered with updating vCard itself, the IETF has a working group building a read-write standard for sharing address book data called CardDAV. (It’s a set of extensions to WebDAV for contact info, hence the name.) Since Portable Contacts is also trying to create a standard for accessing contact into online (albeit with a less ambitious scope and feature set), I was eager to share the design decisions we had made and the promising early adoption we’ve already seen.
My optimistic hope was that perhaps some of our insights might end up influencing the direction of CardDAV–or perhaps even vCard itself. But I was also a bit nervous that such an august and rigorous standards body might have little interest in the pontifications of a “scrappy Open Stack hacker” like me. Or that even if they liked what I said, it might be impossible to have an impact this late in the game. But I figured if nothing else, here’s a group of people that are as passionate about the gory details of contact info as we are, so at least we should meet one another and see where it leads.
Boy was I impressed and inspired by their positive reception of my remarks! Far from being a hostile or dis-interested audience, everyone seemed genuinely excited by the work we’d done, especially since companies large and small are already shipping compliant implementations. The Q&A was passionate and detailed, and it spilled out into the hallway and continued long after the session officially ended.
Best of all, I then got to sit down with Simon Perreault, one of the primary authors of vCard 4.0 and vCardXML, and we went literally line-by-line through the entire Portable Contacts spec and wrote a list of all the ways if differs from the next proposed version of vCard. As you might imagine, there were some passionate arguments on both sides concerning the details, but actually there were really no “deal breakers” in there, and Simon sounded quite open (or even excited) about some of the “innovations” we’d made. It really does look like we might be able to get a common XML schema across PoCo and vCard / CardDAV, and some of the changes might well land in core vCard!
Of course, any official spec changes will happen through the normal IETF mailing lists and process. But as I’m sure you can tell, I think things went amazingly well today, and the future of standards for sharing contact info online has never looked brighter! Thanks again to Marc Blanchet, Cyrus Daboo, and the rest of the vCardDAV working group for their invitation and warm reception. Onward ho!
Watch full video (via Brightcove)
I flew down to an oddly-lush oasis in the middle of the desert last week to attend a panel at DEMO about the future of the social web. Max Engel from MySpace has a nice write-up of the event, and a full video of our panel is available on Brightcove. Eric Eldon of VentureBeat moderated the panel, which featured me, Max Engel, Dave Morin from Facebook, and Kevin Marks from Google. In addition to a lively discussion, we each demoed our “latest and greatest” efforts at opening up the social web. Max showed the first public demo of MySpace’s support for hybrid OpenID+OAuth login using a friendly popup, Kevin showed off how to add FriendConnect to any blog, and Dave showed off some new examples of Facebook Connect in the wild. I showed our new Google-optimized onboarding experiment with Plaxo, and revealed that it’s working so well that we’re now using it for 100% of new users invited to Plaxo via a gmail.com email address.
It’s just amazing and inspiring to me that these major mainstream internet sites are all now able to stand up and demo slick, user-friendly cross-site interoperability and data sharing using open APIs, and we’re all continuing to converge on common standards so developers don’t have to write separate code to interoperate with each site. You can really measure the speed of progress in this space by watching the quantity and quality of these Open Web demos continue to increase, and with SXSW, Web 2.0 Expo, Google I/O, and Internet Identity Workshop all still to come in the first half of 2009, I have a feeling that we all ain’t seen nuthin’ yet! 🙂
Yesterday one of my wife’s friends came over to visit, and we decided on a lark to watch the Oscars (which we haven’t done most years). Even though we pay for Cable and are avid TiVo users, due to a variety of circumstances we missed both the beginning of the Oscars and–more importantly–the entire finale, from best female actress through best picture. My frustration and indignation led to me to think systematically about the various ways that technology could and should have helped us avoid this problem. I decided to share my thoughts in the hope that better understanding technology’s current limitations will help inspire and illuminate the way to improving them. As usual, I welcome your feedback, comments, and additional thoughts on this topic.
The essence of the failure was this: the Oscars was content that we wanted to watch, we were entitled to watch, but were ultimately unable to watch. But specifically, here’s what went wrong that could and should have done better:
Nothing alerted me that the Oscars was even on that day, nor did it prompt me to record it. I happened to return home early that day from the Plaxo ski trip, but might well have otherwise missed it completely. This is ridiculous given that the Oscars is a big cultural event in America, and that lots of people were planning to watch and record it. That “wisdom of the crowds” should have caused TiVo or someone to send me an email or otherwise prompt me to ask “Lots of people are planning to watch the Oscars–should I TiVo that for you?”
As a result of not having scheduled the Oscars to record in advance, when we turned on the TV it turned out that the red carpet pre-show had started 15 minutes ago. Sadly, there was no way to go back and watch the 15 minutes we had missed. Normally TiVo buffers the last 30 minutes of live TV, but when you change channels, it wipes out the buffer, and in this case we were not already on the channel where the Oscars were being recorded. Yet clearly this content could and should be easily accessible, especially when it just happened–you could imagine a set of servers in the cloud buffering the last 30 minutes of each channel, and then providing a similar TiVo-like near-past rewind feature no matter which channel you happen to change to (this would be a lot easier than full on-demand since the last 30 minutes of all channels is a tiny subset of the total content on TV).
Once we started watching TV and looked at the schedule, we told TiVo to record the Oscars, but elected to skip the subsequent Barbara Walters interview or whatever was scheduled to follow. Part way through watching in near-real-time, my wife and her friend decided to take a break and do something else (a luxury normally afforded by TiVo). When they came back to finish watching, we discovered to our horror that the Oscars had run 30+ minutes longer than scheduled, and thus we had missed the entire finale. We hadn’t scheduled anything to record after the Oscars, so TiVo in theory could have easily recorded this extra material, but we hadn’t told it to do so, and it didn’t know the program had run long, and its subsequent 30-minute buffer had passed over the finale hours ago, so we were sunk. There are multiple failures at work here:
TiVo didn’t know that the Oscars would run long or that it was running long. My intent as a user was “record the Oscars in its entirety” but what actually happens is TiVo looks at the (static and always-out-of-date) program guide data and says “ok, I’ll record channel 123 from 5:30pm until 8:30pm and hope that does the trick”. Ideally TiVo should get updated program guide data on-the-fly when a program runs long, or else it should be able to detect that the current program has not yet ended and adjust its recording time appropriately. In absence of those capabilities, TiVo has a somewhat hackish solution of knowing which programs are “live broadcasts” and asking you “do you want to append extra recording time just in case?” when you go to record the show. We would have been saved if we’d chosen to do so, but that brings me to…
We had no information that the Oscars was likely to run long. Actually, that’s not entirely true. Once we discovered our error, my wife’s friend remarked, “oh yeah, the Oscars always runs long”. Well, in that case, there should be ample historical data of the expected chance that a repeated live event like the Oscars should have extra time appended to the recording, and TiVo should be able to present that data to help its users make a more informed choice about whether to add additional recording time. If failure #1 was addressed, this whole issue would me moot, but in the interim, if TiVo is going to pass the buck to its users to decide when to add recording time, it should at least gather enough information to help the user make an informed choice.
We weren’t able to go back and watch the TV we had missed, even though nothing else was being recorded during that time. Even though we hadn’t specifically told TiVo to record past the scheduled end of the Oscars, we also hadn’t told it to record anything else. So it was just sitting there, on the channel we wanted to record, doing nothing. Well, actually it was buffering more content, but only for 30 minutes, and only until it changed channels a few hours later to record some other pre-scheduled show. With hard drives as cheap as they are today, there’s no reason TiVo couldn’t have kept recording that same channel until it was asked to change channels. You could easily imagine an automatic overrun-prevention scheme where TiVo keeps recording say an extra hour after each scheduled show (unless it’s asked to change channels in the interim) and holds that in a separate, low-priority storage area (like the suggestions it records when extra space is free) that’s available to be retrieved at the end of a show (“The scheduled portion of this show has now ended, but would you like to keep watching?”), provided you watch that show soon after it was first recorded. In this case, it was only a few hours after the scheduled show had ended, so TiVo certainly would have had the room and ability to do this for us.
Dismayed at our failure to properly record the Oscars finale, we hoped that online content delivery had matured to the point where we could just watch the part we had missed online. After all, this is a major event on a broadcast channel whose main point is to draw attention to the movie industry, so if there were ever TV content whose owners should be unconflicted about maximizing viewership in any form, this should be it. But again, here we failed. First of all, there was no way to go online without seeing all the results, thus ruining the suspense we were hoping to experience. One could easily imagine first asking users if they had seen the Oscars, and having a separate experience for those wanting to watch it for the first time vs. those merely wanting a summary or re-cap. But even despite that setback, there was no way to watch the finale online in its entirety. The official Oscars website did have full video of the acceptance speeches, which was certainly better than nothing, but we still missed the introductions, the buildup, and so on. It blows my mind that you still can’t go online and just watch the raw feed, even of a major event on a broadcast channel like ABC, even when the event happened just a few hours ago. In this case it seems hard to believe that the hold-up would be a question of whether the viewer is entitled to view this content (compared to, say, some HBO special or a feature-length movie), but even if it were, my cable company knows that I pay to receive ABC, and presumably has this information available digitally somewhere. Clips are nice, but ABC must have thought the Oscars show was worth watching in its entirety (since it broadcast the whole thing), so there should be some way to watch it that way online, especially soon after it aired (again, this is a simpler problem than archiving all historical TV footage for on-demand viewing). Of course, there is one answer here: I’m sure I could have found the full Oscars recording on bittorrent and downloaded it. How sad (if not unexpected) that the “pirates” are the closest ones to delivering the user experience that the content owners themselves should be striving for!
Finally, aside from just enabling me to passively consume this content I wanted, I couldn’t help but notice a lot of missed opportunity to make watching the Oscars a more compelling, consuming, and social experience. For instance, I had very little context about the films and nominees–which were expected to win? Who had won or been nominated before? Which were my friends’ favorites? In some cases, I didn’t even know which actors had been in which films, or how well those films had done (both in the box office and with critics). An online companion to the Oscars could have provided all of this information, and thus drawn me in much more deeply. And with a social dimension (virtually watching along with my friends and seeing their predictions and reactions), it could have been very compelling indeed. If such information was available Online, the broadcast certainly didn’t try to drive any attention there (not even a quick banner under the show saying “Find out more about all the nominees at Oscar.com”, at least not that I saw). And my guess is that whatever was online wasn’t nearly interactive enough or real-time enough for the kind of “follow along with the show and learn more as it unfolds” type of experience I’m imagining. And even if such an experience were built, my guess is it would only be real-time with the live broadcast. But there’s no reason it couldn’t prompt you to click when you’ve seen each award being presented (even if watching later on your TiVo) and only then revealing the details of how your pick compared to your friends and so on.
So in conclusion, I think there’s so much opportunity here to make TV content easier and more reliable to consume, and there’s even more opportunity to make it more interactive and social. I know I’m not the first person to realize this, but it still amazes me when you really think in detail about the current state of the art how many failures and opportunities there are right in front of us. As anyone who knows me is painfully aware, I’m a huge TiVo fan, but in this case TiVo let me down. It wasn’t entirely TiVo’s fault, of course, but the net result is the same. And in terms of making the TV experience more interactive and social, it seems like the first step is to get a bunch of smart Silicon Valley types embedded in the large cable companies, especially the ones that aren’t scared of the internet. Well, personally I’m feeling pretty good about that one. 😉
I recentlyhelped Dave Winer debug his OAuth Consumer code, and the process was more painful than it should have been. (He was trying to write a Twitter app using their beta OAuth support, and since he has his own scripting environment for his OPML editor, there wasn’t an existing library he could just drop in.) Now I’m a big fan of OAuth–it’s a key piece of the Open Stack, and it really does work well once you get it working. I’ve written both OAuth Provider and Consumer code in multiple languages and integrated with OAuth-protected APIs on over half a dozen sites. I’ve also helped a lot of developers and companies debug their OAuth implementations and libraries. And the plain truth is this: it’s empirically way too painful still for first-time OAuth developers to get their code working, and despite the fact that OAuth is a standard, the empirical “it-just-works-rate” is way too low.
We in the Open Web community should all be concerned about this, since OAuth is the “gateway” to most of the open APIs we’re building, and quite often this first hurdle is the hardest one in the entire process. That’s not the “smooth on-ramp” we should be striving for here. We can and should do better, and I have a number of suggestions for how to do just that.
To some extent, OAuth will always be “hard” in the sense that it’s crypto–if you get one little bit wrong, the whole thing doesn’t work. The theory is, “yeah it might be hard the first time, but at least you only have to suffer that pain once, and then you can use it everywhere”. But even that promise falls short because most OAuth libraries and most OAuth providers have (or have had) bugs in them, and there aren’t good enough debugging, validating, and interop tools available to raise the quality bar without a lot of trial-and-error testing and back-and-forth debugging. I’m fortunate in that a) I’ve written and debugged OAuth code so many times that I”m really good at it now, and b) I personally know developers at most of the companies shipping OAuth APIs, but clearly most developers don’t have those luxuries, nor should they have to.
After I helped Dave get his code working, he said “you know, what you manually did for me was perfect. But there should have been a software tool to do that for me automatically”. He’s totally right, and I think with a little focused effort, the experience of implementing and debugging OAuth could be a ton better. So here are my suggestions for how to help make implementing OAuth easier. I hope to work on some or all of these in my copious spare time, and I encourage everyone that cares about OAuth and the Open Stack to pitch in if you can!
Write more recipe-style tutorials that take developers step-by-step through the process of building a simple OAuth Consumer that works with a known API in a bare-bones, no-fluff fashion. There are some good tutorials out there, but they tend to be longer on theory and shorter on “do this, now do this, now you should see that, …”, which is what developers need most to get up and running fast. I’ve written a couple such recipes so far–one for becoming an OpenID relying party, and one for using Netflix’s API–and I’ve gotten tremendous positive feedback on both, so I think we just need more like that.
Build a “transparent OAuth Provider” that shows the consumer exactly what signature base string, signature key, and signature it was expecting for each request. One of the most vexing aspects of OAuth is that if you make a mistake, you just get a 401 Unauthorized response with little or no debugging help. Clearly in a production system, you can’t expect the provider to dump out all the secrets they were expecting, but there should be a neutral dummy-API/server where you can test and debug your basic OAuth library or code with full transparency on both sides. In addition, if you’re accessing your own user-data on a provider’s site via OAuth, and you’ve logged in via username and password, there should be a special mode where you can see all the secrets, base strings, etc. that they’re expecting when you make an OAuth-signed request. (I plan to add this to Plaxo, since right now I achieve it by grepping through our logs and them IMing with the developers who are having problems, and this is, uhh, not scalable.)
Build an OAuth validator for providers and consumersthat simulates the “other half” of the library (i.e. a provider to test consumer-code and a consumer to test provider-code) and that takes the code through a bunch of different scenarios, with detailed feedback at each step. For instance, does the API support GET? POST? Authorization headers? Does it handle empty secrets properly? Does it properly encode special characters? Does it compute the signature properly for known values? Does it properly append parameters to the oauth_callback URL when redirecting? And so on. I think the main reason that libraries and providers so far have all had bugs is that they really didn’t have a good way to thoroughly test their code. As a rule, if you can’t test your code, it will have bugs. So if we just encoded the common mistakes we’ve all seen in the field so far and put those in a validator, future implementations could be confident that they’ve nailed all the basics before being released in the wild. (And I’m sure we’d uncover more bugs in our existing libraries and providers in the process!)
Standardize the terms we useboth in our tutorials and libraries. The spec itself is pretty consistent, but it’s already confusing enough to have a “Consumer Token”, “Request Token”, and “Access Token”, each of which consist of a “Token Key” and “Token Secret”, and it’s even more confusing when these terms aren’t used with exact specificity. It’s too easy to just say “token” to mean “request token” or “token” to mean “token key”–I do it all the time myself, but we really need to keep ourselves sharp when trying to get developers to do the right thing. Worse still, all the existing libraries use different naming conventions for the functions and steps involved, so it’s hard to write tutorials that work with multiple libraries. We should do a better job of using specific and standard terms in our tutorials and code, and clean up the stuff that’s already out there.
Consolidate the best libraries and other resourcesso developers have an easier time finding out what the current state-of-the-art is. Questions that should have obvious and easily findable answers include: is there an OAuth library in my language? If so, what’s the best one to use? How much has it been tested? Are their known bugs? Who should I contact if I run into problems using it? What are the current best tutorials, validators, etc. for me to use? Which companies have OAuth APIs currently? What known issues exist for each of those providers? Where is the forum/mailing-list/etc for each of those APIs? Which e-mail list(s) should I send general OAuth questions to? Should I feel confident that emails sent to those lists will receive prompt replies? Should I expect that bug reports or patches I submit there will quickly find their way to the right place? And so on.
Share more war storiesof what we’ve tried, what hasn’t worked, and what we had to do to make it work. I applauded Dave for suffering his developer pain in public via his blog, and I did the same when working with Netflix’s API, but if we all did more of that, our collective knowledge of bugs, patterns, tricks, and solutions would be out there for others to find and benefit form. I should do more of that myself, and if you’ve ever tried to use OAuth, write an OAuth library, or build your own provider, you should too! So to get things started: In Dave’s case, the ultimate problem turned out to be that he was using his Request Secret instead of his Access Secret when signing API requests. Of course this worked when hitting the OAuth endpoint to get his Access token in the first place, and it’s a subtle difference (esp. if you don’t fully grok what all these different tokens are for, which most people don’t), but it didn’t work when hitting a protected API, and there’s no error message on any provider that says “you used the wrong secret when signing your request” since the secrets are never transmitted directly. The way I helped him debug it was to literally watch our debugging logs (which spit out all the guts of the OAuth signing process, including Base String, Signature Key, and final Signature), and then I sent him all that info and asked him to print out the same info on his end and compare the two. Once he did that, it was easy to spot and fix the mistake. But I hope you can see how all of the suggestions above would have helped make this process a lot quicker and less painful.
What else can we as a community do to make OAuth easier for developers? Add your thoughts here or in your own blog post. As Dave remarked to me, “the number of OAuth developers out there is about to skyrocket” now that Google, Yahoo, MySpace, Twitter, Netflix, TripIt, and more are providing OAuth-protected APIs. So this is definitely the time to put in some extra effort to make sure OAuth can really achieve its full potential!
The quest to open up the Social Web is quickly shifting from a vision of the future to a vision of the present. Last week we reached an important milestone in delivering concrete benefits to mainstream users from the Open Stack. Together with Google, we released a new way to join Plaxo–without having to create yet-another-password or give away your existing password to import an address book. We’re using a newly developed “hybrid protocol” that blends OpenID and OAuth so Gmail users (or any users of a service supporting these open standards) can, in a single act of consent, create a Plaxo account (using OpenID) and grant access to the data they wish to share with Plaxo (using OAuth).
We’re testing this new flow on a subset of Plaxo invites sent to @gmail.com users, which means we can send those users through this flow without having to show them a long list of possible Identity Provider choices, and without them having to know their own OpenID URL. The result is a seamless and intuitive experience for users (“Hey Plaxo, I already use Gmail, use that and don’t make me start from scratch”) and an opportunity for both Plaxo and Google to make our services more interoperable while reducing friction and increasing security. I’m particularly excited about this release because it’s a great example of “putting the pieces together” (combining multiple Open Stack technologies in such a way that the whole is greater than the sum of the parts), and it enables an experience that makes a lot of sense for mainstream users, who tend to think of “using an existing account” as a combination of identity (“I already have a gmail password”) and data (“I already have a gmail address book”). And, of course, because this integration is based on open standards, it will be easy for both Google and Plaxo to turn around and do similiar integrations with other sites, not to mention that the lessons we learn from these experiments will be helpful to any sites that want to build a similar experience.
To learn more about this integration, you can read Plaxo’s blog post and the coverage on TechCrunch, VentureBeat, or ReadWriteWeb (which got syndicated to The New York Times, neat!), and of course TheSocialWeb.tv. But I thought I’d take a minute to explain a bit more about how this integration works “under the hood”, and also share a bit of the backstory on how it came to be.
Under the hood
For those interested in the details of how the OpenID+OAuth hybrid works, and how we’re using it at Plaxo, here’s the meat: it’s technically an “OAuth Extension” for OpenID (using the standard OpenID extension mechanism already used by simple registration and attribute exchange) where the Relying Party asks the Identity Provider for an OAuth Request Token (optionally limited to a specific scope, e.g. “your address book but not your calendar data”) as part of the OpenID login process. The OP recognizes this extension and informs the user of the data the RP is requesting as part of the OpenID consent page. If the user consents, the OP sends back a pre-authorized OAuth Request Token in the OpenID response, which the RP can then exchange for a long-lived Access Token following the normal OAuth mechanism.
Note that RPs still need to obtain an OAuth Consumer Key and Secret offline beforehand (we’ve worked on ways to support unregistered consumers, but they didn’t make it into the spec yet), but they *don’t* have to get an Unauthorized Request Token before initiating OpenID login. The point of obtaining a Request Token separately is mainly to enable desktop and mobile OAuth flows, where popping open a web browser and receiving a response isn’t feasible. But since OpenID login is always happening in a web browser anyway, it makes sense for the OP to generate and pre-authorize the Request Token and return it via OpenID. This also frees the RP from the burden of having to deal with fetching and storing request tokens–given especially the rise in prominence of “directed identity” logins with OpenID (e.g. the RP just shows a “sign in with your Yahoo! account” button, which sends the OpenID URL “yahoo.com” and relies on the OP to figure out which user is logging in and return a user-specific OpenID URL in the response), the RP often can’t tell in advance which user is trying to log in and whether they’ve logged in before, and thus in the worst case they might otherwise have to generate a Request Token before every OpenID login, even though the majority of such logins won’t end up doing anything with that token. Furthermore, the OP can feel confident that they’re not inadvertently giving away access to the user’s private data to an attacker, because a) they’re sending the request token back to the openid.return_to URL, which has to match the openid.realm which is displayed to the user (e.g. if the OP says “Do you trust plaxo.com to see your data”, they know they’ll only send the token back to a plaxo.com URL), and b) they’re only sending the Request Token in the “front channel” of the web browser, and the RP still has to exchange it for an Access Token on the “back channel” of direct server-to-server communication, which also requires signing with a Consumer Secret. In summary, the hybrid protocol is an elegant blend of OpenID and OAuth that is relatively efficient on the wire and at least as secure as each protocol on their own, if not more so.
Once a user signs up for Plaxo using the hybrid protocol, we can create an account for them that’s tied to their OpenID (using the standard recipe) and then attach the OAuth Access Token/Secret to the new user’s account. Then instead of having to ask the user to choose from a list of webmail providers to import their address book from, we see that they already have a valid Gmail OAuth token and we can initiate an automatic import for them–no passwords required! (We’re currently using Google’s GData Contacts API for the import, but as I demoed in December at the Open Stack Meetup, soon we will be able to use Portable Contacts instead, completing a pure Open Stack implementation.) Finally, when the user has finished setting up their Plaxo account, we show them a one-time “education page” that tells them to click “Sign in with your Google account” next time they return to Plaxo, rather than typing in a Plaxo-specific email and password (since they don’t have one).
However, because Google’s OP supports checkid_immediate, and because Plaxo sets a cookie when a user logs in via OpenID, in most cases we can invisibly and automatically keep the user logged into Plaxo as long as they’re still logged into Gmail. Specifically, if the user is not currently logged into Plaxo, but they previously logged in via OpenID, we attempt a checkid_immediate login (meaning we redirect to the OP and ask them if the user is currently logged in, and the OP immediately redirects back to us and tells us one way or the other). If we get a positive response, we log the user into Plaxo again, and as far as the user can tell, they were never signed out. If we get a negative response, we set a second cookie to remember that checkid_immediate failed, so we don’t try it again until the user successfully signs in. But the net result is that even though the concept of logging into Plaxo using your Google account may take some getting used to for mainstream users, most users will just stay automatically logged into Plaxo (as long as they stay logged into Gmail, which for most Gmail users is nearly always).
The backstory
The concept of combining OpenID and OAuth has been around for over a year. After all, they share a similar user flow (bounce over to provider, consent, bounce back to consumer with data), and they’re both technologies for empowering users to connect the websites they use (providing the complementary capabilities of Authentication and Authorization, respectively). David Recordon and I took a first stab at specifying an OpenID OAuth Extension many months ago, but the problem was there were no OpenID Providers that also supported OAuth-protected APIs yet, so it wasn’t clear who could implement the spec and help work out the details. (After all, OAuth itself was only finalized as a spec in December 07!). But then Google started supporting OAuth for its GData APIs, and they subsequently became an OpenID provider. Yahoo! also became hybrid-eligible (actually, they became an OpenID provider before Google, and added OAuth support later as part of Y!OS), and MySpace adopted OAuth for its APIs and shared their plans to become an OpenID provider as part of their MySpaceID initiative. Suddenly, there was renewed interest in finishing up the hybrid spec, and this time it was from people in a position to get the details right and then ship it.
The Google engineers had a bunch of ideas about clever ways to squeeze out extra efficiency when combining the two protocols (e.g. piggybacking the OAuth Request Token call on the OpenID associate call, or piggybacking the OAuth Access Token call on the OpenID check_authentication call). They also pointed out that given their geographically distributed set of data centers, their “front channel” and “back channel” servers might be on separate continents, so assuming that data could instantly be passed between them (e.g. generating a request token in one data center and then immediately showing it on an authorization page from another data center) wouldn’t be trivial (the solution is to use a deterministically encrypted version of the token as its own secret, rather than storing that in a database or distributed cache). As we considered these various proposals, the tension was always between optimizing for efficiency vs. “composability”–there were already a decent number of standalone OpenID and OAuth implementations in the wild, and ideally combining them shouldn’t require drastic modifications to either one. In practice, that meant giving up on a few extra optimizations to decrease overall complexity and increase the ease of adoption–a theme that’s guided many of the Open Stack technologies. As a proof of the progress we made on that front, the hybrid implementation we just rolled out used our existing OpenID implementation as is, and our existing OAuth implementation as is (e.g. that we also used for our recent Netflix integration), with no modifications required to either library. All we did was add the new OAuth extension to the OpenID login, as well as some simple logic to determine when to ask for an OAuth token and when to attach the token to the newly created user. Hurrah!
A few more drafts of the hybrid spec were floated around for a couple months, but there were always a few nagging issues that kept us from feeling that we’d nailed it. Then came the Internet Identity Workshop in November, where we held a session on the state of the hybrid protocol to get feedback from the larger community. There was consensus that we were on the right track, and that this was indeed worth pursuing, but the nagging issues remained. Until that night, when as in IIW tradition we all went to the nearby Monte Carlo bar and restaurant for dinner and drinks. Somehow I ended up at a booth with the OpenID guys from Google, Yahoo, and Microsoft, and we started rehashing those remaining issues and thinking out loud together about what to do. Somehow everything started falling into place, and one by one we started finding great solutions to our problems, in a cascade that kept re-energizing us to keep working and keep pushing. Before I knew it, it was after midnight and I’d forgotten to ever eat any dinner, but by George we’d done it! I drove home and frantically wrote up as many notes from the evening as I could remember. I wasn’t sure what to fear more–that I would forget the breakthroughs that we’d made that night, or that I would wake up the next morning and realize that what we’d come up with in our late night frenzy was in fact totally broken. 🙂 Thankfully, neither of those things happened, and we ended up with the spec we’ve got today (plus a few extra juicy insights that have yet to materialize).
It just goes to show that there’s still no substitute for locking a bunch of people in a room for hours at a time to focus on a problem. (Though in this case, we weren’t so much locked in as enticed to stay with additional drink tickets, heh.) And it also shows the power of collaborating across company lines by developing open community standards that everyone can benefit from (and thus everyone is incentivized to contribute to). It was one of those amazing nights that makes me so proud and grateful to work in this community of passionate folks trying to put users in control of their data and truly open up the Social Web.
What’s next?
Now that we’ve released this first hybrid experiment, it’s time to analyze the results and iterate to perfection (or as close as we can get). While it’s too early to report on our findings thus far, let me just say that I’m *very* encouraged by the early results we’re seeing. 😉 Stay tuned, because we’ll eagerly share what we’ve learned as soon as we’ve had time to do a careful analysis. I foresee this type of onboarding becoming the norm soon–not just for Plaxo, but for a large number of sites that want to streamline their signup process. And of course the best of part of doing this all with open standards is that everyone can learn along with us and benefit from each other’s progress. Things are really heating up and I couldn’t be more excited to keep forging ahead here!
I’m excited and humbled by the amazing progress we’ve made this year on Portable Contacts, which started out as little more than a few conversations and an aspirational PowerPoint deck this summer. We’ve now got a great community engaged around solving this problem (from companies large and small as well as from the grass-roots), we had a successful Portable Contacts Summit together, we’ve got a draft spec that’s getting pretty solid, we’ve got several implementations inthewild (with many more in the works), we’ve achieved wire-alignment with OpenSocial’s RESTful people API, and we’ve seen how Portable Contacts when combined with other “open building blocks” like OpenID, OAuth, and XRD creates a compelling “Open Stack” that is more than the sum of its parts.
At the recent Open Stack Meetup hosted by Digg, I gave a presentation on the state of Portable Contacts, along with several demos of Portable Contacts in action (and our crew from thesocialweb.tv was on hand to film the entire set of talks). In addition to showing Portable Contacts working with Plaxo, MySpace, OpenSocial, and twitter (via hCard->vCard->PoCo transformers), I was thrilled to be able to give the first public demo of Portable Contacts working live with Gmail. Better still, I was able to demo Google’s hybrid OpenID+OAuth onboarding plus OAuth-protected Portable Contacts Gmail API. In other words, in one fell swoop I was able to sign up for a Plaxo account using my existing Google account, and I was able to bring over my google credentials, my pre-validated gmail.com e-mail address, and my gmail address book–all at once, and all in an open, secure and vendor-neutral way. Now that’s progress worth celebrating!
I have no doubt that we’re on the cusp of what will become the default way to interact with most new websites going forward. The idea that you had to re-create an account, password, profile, and friends-list on every site that you wanted to check out, and that none of that data or activity flowed with you across the tools you used, will soon seem archaic and quaint. And if you think we came a long way in 2008, you ain’t seen nothing yet! There has never been more momentum, more understanding, and more consolidated effort behind opening up the social web, and the critical pieces–yes, including Portable Contacts–are all but in place. 2009 is going to be a very exciting year indeed!
So let me close out this amazing year by saying Thank You to everyone that’s contributed to this movement. Your passion is infectious and your efforts are all having a major and positive impact on the web. I feel increddibly fortunate to participate in this movement, and I know our best days are still ahead of us. Happy New Year!
I was asked to give one of the opening overview talks at the Internet Identity Workshop about how the “Open Stack” is getting mainstream sites interested in supporting OpenID, OAuth, and Portable Contacts, because the combined value these technologies offer together is greater than the sum of their parts. Having learned so much myself at previous IIWs, it was both an honor and a unique challenge to address this crowd and do them justice–the audience is a mix of super-savvy veterans and new people just getting interested in the space, and I wanted to please everybody. So I put together a new talk with a new core message: the Open Stack is greater than the sum of its parts, and together these building blocks are delivering enough value to make the proposition a win-win-win for developers, users, and site owners to adopt and embrace.
The talk was well received, and it led to a lively discussion afterwards in the break and at dinner. I can’t wait to see what sessions people will call over the next two days to discuss these issues in more depth. It was certainly a joy to be able to demo running code on Yahoo, Google, and MySpace as part of my talk–this is no longer a theoretical exercise when it comes to talking about putting these standards to work! I was even able to show off a newly developed Android app that uses OAuth and Portable Contacts to allow import into your cell phone from an arbitrary address book. I just found about the app this morning–now that’s the Open Stack in action!
As usual, John McCrea covered the event and provides a great write-up with pictures.
 My basic message was this: we’ve made a lot of progress, but we’ve still got a lot left to do. So let’s re-double our efforts and commit ourselves once again to working together and solving these remaining problems. As much success as OpenID has had to date, its continued relevance is by no means guaranteed. But I remain optimistic because the same group of people that have brought us this far are still engaged, and none of the remaining challenges are beyond our collective ability to solve.
My basic message was this: we’ve made a lot of progress, but we’ve still got a lot left to do. So let’s re-double our efforts and commit ourselves once again to working together and solving these remaining problems. As much success as OpenID has had to date, its continued relevance is by no means guaranteed. But I remain optimistic because the same group of people that have brought us this far are still engaged, and none of the remaining challenges are beyond our collective ability to solve.
 I
I 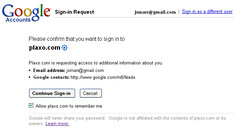

 I’m excited and humbled by the amazing progress we’ve made this year on
I’m excited and humbled by the amazing progress we’ve made this year on 
