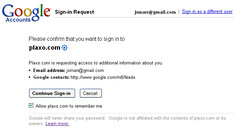
 The quest to open up the Social Web is quickly shifting from a vision of the future to a vision of the present. Last week we reached an important milestone in delivering concrete benefits to mainstream users from the Open Stack. Together with Google, we released a new way to join Plaxo–without having to create yet-another-password or give away your existing password to import an address book. We’re using a newly developed “hybrid protocol” that blends OpenID and OAuth so Gmail users (or any users of a service supporting these open standards) can, in a single act of consent, create a Plaxo account (using OpenID) and grant access to the data they wish to share with Plaxo (using OAuth).
The quest to open up the Social Web is quickly shifting from a vision of the future to a vision of the present. Last week we reached an important milestone in delivering concrete benefits to mainstream users from the Open Stack. Together with Google, we released a new way to join Plaxo–without having to create yet-another-password or give away your existing password to import an address book. We’re using a newly developed “hybrid protocol” that blends OpenID and OAuth so Gmail users (or any users of a service supporting these open standards) can, in a single act of consent, create a Plaxo account (using OpenID) and grant access to the data they wish to share with Plaxo (using OAuth).
We’re testing this new flow on a subset of Plaxo invites sent to @gmail.com users, which means we can send those users through this flow without having to show them a long list of possible Identity Provider choices, and without them having to know their own OpenID URL. The result is a seamless and intuitive experience for users (“Hey Plaxo, I already use Gmail, use that and don’t make me start from scratch”) and an opportunity for both Plaxo and Google to make our services more interoperable while reducing friction and increasing security. I’m particularly excited about this release because it’s a great example of “putting the pieces together” (combining multiple Open Stack technologies in such a way that the whole is greater than the sum of the parts), and it enables an experience that makes a lot of sense for mainstream users, who tend to think of “using an existing account” as a combination of identity (“I already have a gmail password”) and data (“I already have a gmail address book”). And, of course, because this integration is based on open standards, it will be easy for both Google and Plaxo to turn around and do similiar integrations with other sites, not to mention that the lessons we learn from these experiments will be helpful to any sites that want to build a similar experience.
To learn more about this integration, you can read Plaxo’s blog post and the coverage on TechCrunch, VentureBeat, or ReadWriteWeb (which got syndicated to The New York Times, neat!), and of course TheSocialWeb.tv. But I thought I’d take a minute to explain a bit more about how this integration works “under the hood”, and also share a bit of the backstory on how it came to be.
Under the hood
For those interested in the details of how the OpenID+OAuth hybrid works, and how we’re using it at Plaxo, here’s the meat: it’s technically an “OAuth Extension” for OpenID (using the standard OpenID extension mechanism already used by simple registration and attribute exchange) where the Relying Party asks the Identity Provider for an OAuth Request Token (optionally limited to a specific scope, e.g. “your address book but not your calendar data”) as part of the OpenID login process. The OP recognizes this extension and informs the user of the data the RP is requesting as part of the OpenID consent page. If the user consents, the OP sends back a pre-authorized OAuth Request Token in the OpenID response, which the RP can then exchange for a long-lived Access Token following the normal OAuth mechanism.
Note that RPs still need to obtain an OAuth Consumer Key and Secret offline beforehand (we’ve worked on ways to support unregistered consumers, but they didn’t make it into the spec yet), but they *don’t* have to get an Unauthorized Request Token before initiating OpenID login. The point of obtaining a Request Token separately is mainly to enable desktop and mobile OAuth flows, where popping open a web browser and receiving a response isn’t feasible. But since OpenID login is always happening in a web browser anyway, it makes sense for the OP to generate and pre-authorize the Request Token and return it via OpenID. This also frees the RP from the burden of having to deal with fetching and storing request tokens–given especially the rise in prominence of “directed identity” logins with OpenID (e.g. the RP just shows a “sign in with your Yahoo! account” button, which sends the OpenID URL “yahoo.com” and relies on the OP to figure out which user is logging in and return a user-specific OpenID URL in the response), the RP often can’t tell in advance which user is trying to log in and whether they’ve logged in before, and thus in the worst case they might otherwise have to generate a Request Token before every OpenID login, even though the majority of such logins won’t end up doing anything with that token. Furthermore, the OP can feel confident that they’re not inadvertently giving away access to the user’s private data to an attacker, because a) they’re sending the request token back to the openid.return_to URL, which has to match the openid.realm which is displayed to the user (e.g. if the OP says “Do you trust plaxo.com to see your data”, they know they’ll only send the token back to a plaxo.com URL), and b) they’re only sending the Request Token in the “front channel” of the web browser, and the RP still has to exchange it for an Access Token on the “back channel” of direct server-to-server communication, which also requires signing with a Consumer Secret. In summary, the hybrid protocol is an elegant blend of OpenID and OAuth that is relatively efficient on the wire and at least as secure as each protocol on their own, if not more so.
Once a user signs up for Plaxo using the hybrid protocol, we can create an account for them that’s tied to their OpenID (using the standard recipe) and then attach the OAuth Access Token/Secret to the new user’s account. Then instead of having to ask the user to choose from a list of webmail providers to import their address book from, we see that they already have a valid Gmail OAuth token and we can initiate an automatic import for them–no passwords required! (We’re currently using Google’s GData Contacts API for the import, but as I demoed in December at the Open Stack Meetup, soon we will be able to use Portable Contacts instead, completing a pure Open Stack implementation.) Finally, when the user has finished setting up their Plaxo account, we show them a one-time “education page” that tells them to click “Sign in with your Google account” next time they return to Plaxo, rather than typing in a Plaxo-specific email and password (since they don’t have one).
However, because Google’s OP supports checkid_immediate, and because Plaxo sets a cookie when a user logs in via OpenID, in most cases we can invisibly and automatically keep the user logged into Plaxo as long as they’re still logged into Gmail. Specifically, if the user is not currently logged into Plaxo, but they previously logged in via OpenID, we attempt a checkid_immediate login (meaning we redirect to the OP and ask them if the user is currently logged in, and the OP immediately redirects back to us and tells us one way or the other). If we get a positive response, we log the user into Plaxo again, and as far as the user can tell, they were never signed out. If we get a negative response, we set a second cookie to remember that checkid_immediate failed, so we don’t try it again until the user successfully signs in. But the net result is that even though the concept of logging into Plaxo using your Google account may take some getting used to for mainstream users, most users will just stay automatically logged into Plaxo (as long as they stay logged into Gmail, which for most Gmail users is nearly always).
The backstory
The concept of combining OpenID and OAuth has been around for over a year. After all, they share a similar user flow (bounce over to provider, consent, bounce back to consumer with data), and they’re both technologies for empowering users to connect the websites they use (providing the complementary capabilities of Authentication and Authorization, respectively). David Recordon and I took a first stab at specifying an OpenID OAuth Extension many months ago, but the problem was there were no OpenID Providers that also supported OAuth-protected APIs yet, so it wasn’t clear who could implement the spec and help work out the details. (After all, OAuth itself was only finalized as a spec in December 07!). But then Google started supporting OAuth for its GData APIs, and they subsequently became an OpenID provider. Yahoo! also became hybrid-eligible (actually, they became an OpenID provider before Google, and added OAuth support later as part of Y!OS), and MySpace adopted OAuth for its APIs and shared their plans to become an OpenID provider as part of their MySpaceID initiative. Suddenly, there was renewed interest in finishing up the hybrid spec, and this time it was from people in a position to get the details right and then ship it.
The Google engineers had a bunch of ideas about clever ways to squeeze out extra efficiency when combining the two protocols (e.g. piggybacking the OAuth Request Token call on the OpenID associate call, or piggybacking the OAuth Access Token call on the OpenID check_authentication call). They also pointed out that given their geographically distributed set of data centers, their “front channel” and “back channel” servers might be on separate continents, so assuming that data could instantly be passed between them (e.g. generating a request token in one data center and then immediately showing it on an authorization page from another data center) wouldn’t be trivial (the solution is to use a deterministically encrypted version of the token as its own secret, rather than storing that in a database or distributed cache). As we considered these various proposals, the tension was always between optimizing for efficiency vs. “composability”–there were already a decent number of standalone OpenID and OAuth implementations in the wild, and ideally combining them shouldn’t require drastic modifications to either one. In practice, that meant giving up on a few extra optimizations to decrease overall complexity and increase the ease of adoption–a theme that’s guided many of the Open Stack technologies. As a proof of the progress we made on that front, the hybrid implementation we just rolled out used our existing OpenID implementation as is, and our existing OAuth implementation as is (e.g. that we also used for our recent Netflix integration), with no modifications required to either library. All we did was add the new OAuth extension to the OpenID login, as well as some simple logic to determine when to ask for an OAuth token and when to attach the token to the newly created user. Hurrah!
 A few more drafts of the hybrid spec were floated around for a couple months, but there were always a few nagging issues that kept us from feeling that we’d nailed it. Then came the Internet Identity Workshop in November, where we held a session on the state of the hybrid protocol to get feedback from the larger community. There was consensus that we were on the right track, and that this was indeed worth pursuing, but the nagging issues remained. Until that night, when as in IIW tradition we all went to the nearby Monte Carlo bar and restaurant for dinner and drinks. Somehow I ended up at a booth with the OpenID guys from Google, Yahoo, and Microsoft, and we started rehashing those remaining issues and thinking out loud together about what to do. Somehow everything started falling into place, and one by one we started finding great solutions to our problems, in a cascade that kept re-energizing us to keep working and keep pushing. Before I knew it, it was after midnight and I’d forgotten to ever eat any dinner, but by George we’d done it! I drove home and frantically wrote up as many notes from the evening as I could remember. I wasn’t sure what to fear more–that I would forget the breakthroughs that we’d made that night, or that I would wake up the next morning and realize that what we’d come up with in our late night frenzy was in fact totally broken. 🙂 Thankfully, neither of those things happened, and we ended up with the spec we’ve got today (plus a few extra juicy insights that have yet to materialize).
A few more drafts of the hybrid spec were floated around for a couple months, but there were always a few nagging issues that kept us from feeling that we’d nailed it. Then came the Internet Identity Workshop in November, where we held a session on the state of the hybrid protocol to get feedback from the larger community. There was consensus that we were on the right track, and that this was indeed worth pursuing, but the nagging issues remained. Until that night, when as in IIW tradition we all went to the nearby Monte Carlo bar and restaurant for dinner and drinks. Somehow I ended up at a booth with the OpenID guys from Google, Yahoo, and Microsoft, and we started rehashing those remaining issues and thinking out loud together about what to do. Somehow everything started falling into place, and one by one we started finding great solutions to our problems, in a cascade that kept re-energizing us to keep working and keep pushing. Before I knew it, it was after midnight and I’d forgotten to ever eat any dinner, but by George we’d done it! I drove home and frantically wrote up as many notes from the evening as I could remember. I wasn’t sure what to fear more–that I would forget the breakthroughs that we’d made that night, or that I would wake up the next morning and realize that what we’d come up with in our late night frenzy was in fact totally broken. 🙂 Thankfully, neither of those things happened, and we ended up with the spec we’ve got today (plus a few extra juicy insights that have yet to materialize).
It just goes to show that there’s still no substitute for locking a bunch of people in a room for hours at a time to focus on a problem. (Though in this case, we weren’t so much locked in as enticed to stay with additional drink tickets, heh.) And it also shows the power of collaborating across company lines by developing open community standards that everyone can benefit from (and thus everyone is incentivized to contribute to). It was one of those amazing nights that makes me so proud and grateful to work in this community of passionate folks trying to put users in control of their data and truly open up the Social Web.
What’s next?
Now that we’ve released this first hybrid experiment, it’s time to analyze the results and iterate to perfection (or as close as we can get). While it’s too early to report on our findings thus far, let me just say that I’m *very* encouraged by the early results we’re seeing. 😉 Stay tuned, because we’ll eagerly share what we’ve learned as soon as we’ve had time to do a careful analysis. I foresee this type of onboarding becoming the norm soon–not just for Plaxo, but for a large number of sites that want to streamline their signup process. And of course the best of part of doing this all with open standards is that everyone can learn along with us and benefit from each other’s progress. Things are really heating up and I couldn’t be more excited to keep forging ahead here!
Liked this post? Follow this blog to get more.