 I like twitter, and I use it a lot (I even a twitter widget on my web site). A lot of my friends use it too, some more regularly than others. I use Bloglines to keep up with the stream of status updates from my twitter friends so I can check in periodically and pick up where I left off.
I like twitter, and I use it a lot (I even a twitter widget on my web site). A lot of my friends use it too, some more regularly than others. I use Bloglines to keep up with the stream of status updates from my twitter friends so I can check in periodically and pick up where I left off.
But increasingly I’m feeling like it’s too easy to miss updates from my friends that don’t post constantly. They just get drowned out in the surging river of tweets from the “power users” I follow. It’s a shame, especially because the infrequent users are often my closer friends, whose messages I really don’t want to miss, whereas the chattier users have (almost by definition) a lower signal-to-noise ratio generally.
I’ve been heads-down at Plaxo this week working on some great open-social-web tools, so when I checked my twitter feed this morning I had 200 unread items (perhaps more, but Bloglines annoyingly caps you at 200 unread items per feed). I scrolled through the long list of updates knowing that probably I wouldn’t notice the messages I cared most about. Technology is not helping me here. But there must be a way to fix it.
Since I’m a self-confessed data-glutton, my first step was to quantify and visualize the problem. So I downloaded the HTML of my 200 unread tweets from Bloglines and pulled out the status messages with a quick grep '<h3' twitter.html | cut -d\> -f3 | cut -d\< -f1 | sort | cut -c1-131 and then counted the number of updates from each user by piping that through cut -d: -f1 | sort | uniq -c (the unix pipe is a text-hacker’s best friend!). Here are the results:
1 adam
2 BarCamp
1 BarCampBlock
2 Blaine Cook
4 Brian Suda
1 Cal Henderson
3 Dave McClure
22 Dave Winer
7 David Weinberger
1 Frederik Hermann
1 Garret Heaton
1 Jajah
3 Jeff Clavier
52 Jeremiah
12 Kevin Marks
10 Lunch 2.0
28 Mr Messina
8 Scott Beale
2 Silona
5 Tantek Celik
20 Tara
10 Tariq KRIM
4 Xeni Jardin
As expected, there were a bunch of users in there with only 1 or 2 status updates that I’d completely missed. And a few users generated the majority of the 200 tweets. I threw the data into excel and spit out a pie chart, which illustrated my subjective experience perfectly:
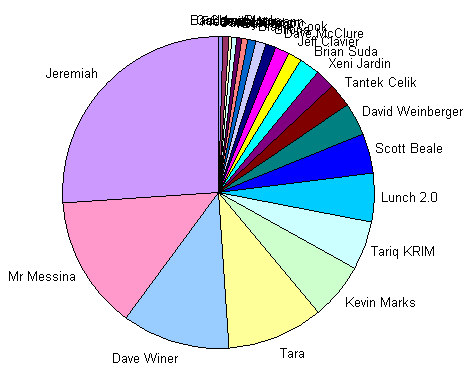
The illegible crowd of names at the top is a wonderfully apt visual representation of the problem. They’re getting trampled in the stampede. And over half of the messages are coming from Jeremiah Owyang, Chris Messina, and Dave Winer (who I suspect will consider this a sign of accomplishment, heh). Now don’t get me wrong, I really want to know what Jeremiah, Chris, and Dave are doing and thinking about, I just don’t want it to be at the expense of that squished group of names at the top, who aren’t quite so loquacious.
But just by doing this experiment, an obvious solution is suggested. Allow a view that groups updates by username and only shows say 1-3 messages per user, with the option to expand and see the rest. This would ensure that you could get a quick view of “who’s said something since I last checked twitter” and it would put everyone on equal footing, regardless of how chatty they are. I could still drill down for the full content, but I wouldn’t feel like I have to wade through my prolific friends to find the muffled chirps of the light twitter users. While there’s clearly value in seeing a chronologically accurate timeline of all status updates, in general I use twitter as another way of keeping in touch with people I care about, so e.g. I think I’d rather know that Garret said something since I last checked in than exactly when he said it.
What do you think? Would this be a useful feature? If so, do we need to wait for Twitter or Bloglines to build it, or would it be easy to do as a mashup? The only hard part I can see is keeping track of the read/unread status, but maybe just keeping a last-read timestamp in a cookie/db and then pulling down all statuses since then and grouping them would be sufficient and quick enough? Now if only I had time for side projects… 🙂
Liked this post? Follow this blog to get more.