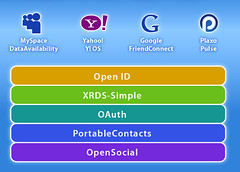
 I’m excited and humbled by the amazing progress we’ve made this year on Portable Contacts, which started out as little more than a few conversations and an aspirational PowerPoint deck this summer. We’ve now got a great community engaged around solving this problem (from companies large and small as well as from the grass-roots), we had a successful Portable Contacts Summit together, we’ve got a draft spec that’s getting pretty solid, we’ve got several implementations in the wild (with many more in the works), we’ve achieved wire-alignment with OpenSocial’s RESTful people API, and we’ve seen how Portable Contacts when combined with other “open building blocks” like OpenID, OAuth, and XRD creates a compelling “Open Stack” that is more than the sum of its parts.
I’m excited and humbled by the amazing progress we’ve made this year on Portable Contacts, which started out as little more than a few conversations and an aspirational PowerPoint deck this summer. We’ve now got a great community engaged around solving this problem (from companies large and small as well as from the grass-roots), we had a successful Portable Contacts Summit together, we’ve got a draft spec that’s getting pretty solid, we’ve got several implementations in the wild (with many more in the works), we’ve achieved wire-alignment with OpenSocial’s RESTful people API, and we’ve seen how Portable Contacts when combined with other “open building blocks” like OpenID, OAuth, and XRD creates a compelling “Open Stack” that is more than the sum of its parts.
At the recent Open Stack Meetup hosted by Digg, I gave a presentation on the state of Portable Contacts, along with several demos of Portable Contacts in action (and our crew from thesocialweb.tv was on hand to film the entire set of talks). In addition to showing Portable Contacts working with Plaxo, MySpace, OpenSocial, and twitter (via hCard->vCard->PoCo transformers), I was thrilled to be able to give the first public demo of Portable Contacts working live with Gmail. Better still, I was able to demo Google’s hybrid OpenID+OAuth onboarding plus OAuth-protected Portable Contacts Gmail API. In other words, in one fell swoop I was able to sign up for a Plaxo account using my existing Google account, and I was able to bring over my google credentials, my pre-validated gmail.com e-mail address, and my gmail address book–all at once, and all in an open, secure and vendor-neutral way. Now that’s progress worth celebrating!
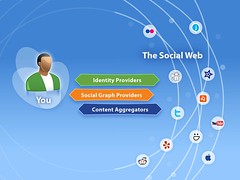
I have no doubt that we’re on the cusp of what will become the default way to interact with most new websites going forward. The idea that you had to re-create an account, password, profile, and friends-list on every site that you wanted to check out, and that none of that data or activity flowed with you across the tools you used, will soon seem archaic and quaint. And if you think we came a long way in 2008, you ain’t seen nothing yet! There has never been more momentum, more understanding, and more consolidated effort behind opening up the social web, and the critical pieces–yes, including Portable Contacts–are all but in place. 2009 is going to be a very exciting year indeed!
So let me close out this amazing year by saying Thank You to everyone that’s contributed to this movement. Your passion is infectious and your efforts are all having a major and positive impact on the web. I feel increddibly fortunate to participate in this movement, and I know our best days are still ahead of us. Happy New Year!
















{kind=link}